İşte Uber’in Trafik Sistemi: Kümeleme ve K-Means Algoritması

Gartner’a göre, 2020 yılına kadar çeyrek milyar bağlantılı araç IoT’nin önemli bir unsurunu oluşturacak. Bağlı araçların gerçek zamanlı izleme ve uygulamalar sağlamak için analiz edilebilen ve yeni mobilite ve araç kullanımı kavramlarına yol açacak şekilde saatte 25 GB veri üretmesi öngörülmektedir. Referans: Gartner
Uber ve Makine Öğrenimi Bağlantısı
Uber, kârı en üst düzeye çıkarmak için fiyatlandırmayı hesaplamaktan otomobillerin en uygun şekilde konumlandırılmasına kadar makine öğrenimini kullanır. Araç GPS verilerinin analizi ve izlenmesi için genel uber yolculuk veri kümesi kullanıldı.
Uber tarafından New York’tan üretilen verileri içeren Uber gezi veri kümesi. Veriler FiveThirtyEight üzerinde ücretsiz olarak mevcut.
Beş ilçesi olan New York City’den veriler: Brooklyn, Queens, Manhattan, Bronx ve Staten Island. Uygulama, Uber’e yapılan seyahatleri anlamak ve New York’taki farklı ilçeleri tanımlamak için bu veri kümesinde Kümeleme anlamına gelir.
Kümeleme, veri kümelerini benzer veri noktalarından oluşan gruplara bölme işlemidir. Kümeleme, etiketlenmemiş verileriniz olduğunda kullanılan bir tür denetimsiz makine öğrenimidir.
Burada, ana amacı benzer öğeleri veya veri noktalarını bir kümede gruplamak olan bir K-Means kümeleme algoritması uyguladık. K-ortalamalarındaki “K”, kümelerin sayısını temsil eder. İnternette, K-Means algoritmasının çalışma prensibini aratarak kontrol edebilirsiniz.
Gerekli kütüphaneleri içe aktarma

CSV okuma
Çıktı
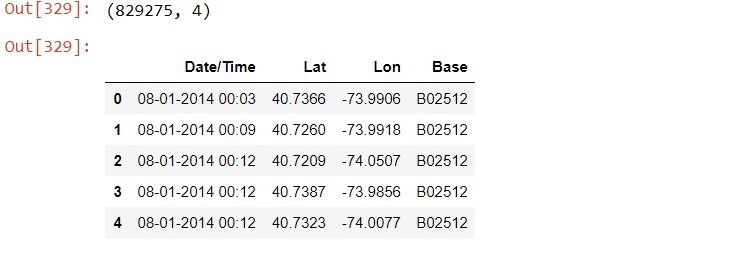
Veri kümesinde 829.275 gözlem ve dört sütun var. İşte bulunan dört özellik:
- Tarih / Saat: Uber toplayıcının tarihi ve saati.
- Lat (Enlem): Uber alıcısının enlemi
- Lon (Boylam): Uber alıcısının boylamı.
- Temel: Uber pikapına bağlı TLC temel şirket kodu.
Özellik seçmek

Çıktı

K-Means kümelenmesi uygulanır. İlk adım K için en uygun değeri bulmaktır. Bu, aşağıda gösterildiği gibi dirsek grafiğinden öğrenilebilir.
Çıktı

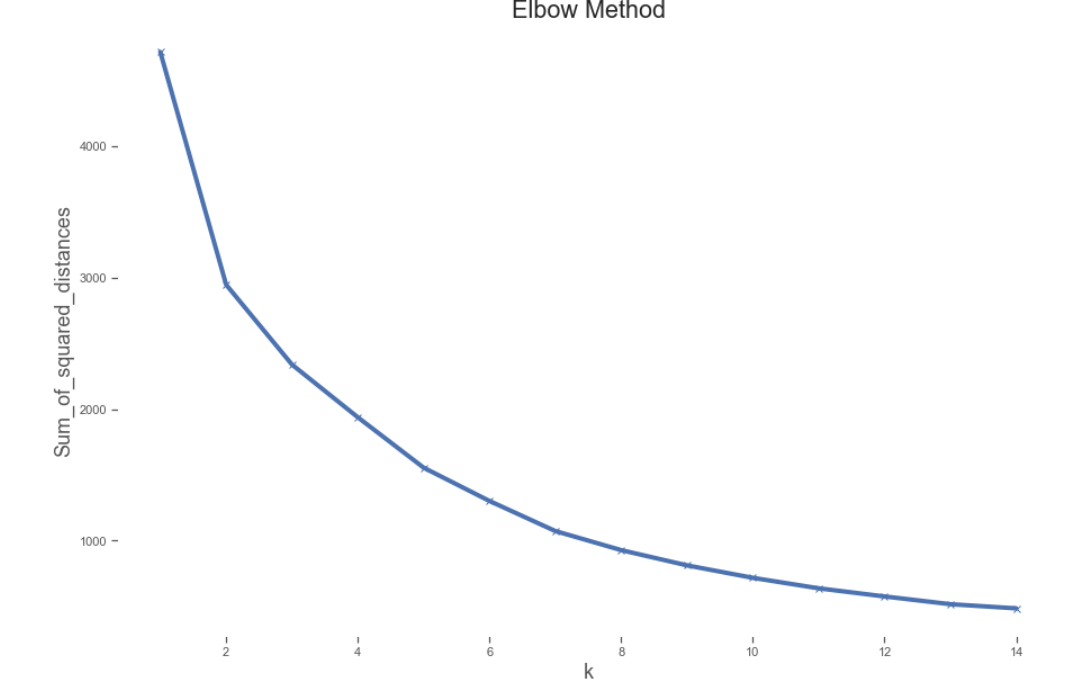
Yukarıdaki dirsek grafiğinden, en yakın küme ağırlık merkezinden gözlemlerin kare mesafesinin toplamının, kümelerin sayısındaki bir artışla azalmaya devam ettiğini görebiliriz. K = 6 sonrası önemli bir azalma olduğunu görebiliriz. 6 veya 7 kümeden birini seçebiliriz. Bu veri kümesi için 6 tane seçildi.
K-Means Kümeleme Yapma
K-Means algoritmasında birkaç küme atama

Küme Ağırlık Merkezlerini Saklama

Çıktı

Ağırlık merkezlerini görselleştirmek

Enlem ve boylamları ağırlık merkezlerinden almak ve iki ayrı veri çerçevesine dönüştürmek. Hem veri çerçevesini birleştirdi hem de kolay görselleştirme için “clocation” olarak adlandırdı.

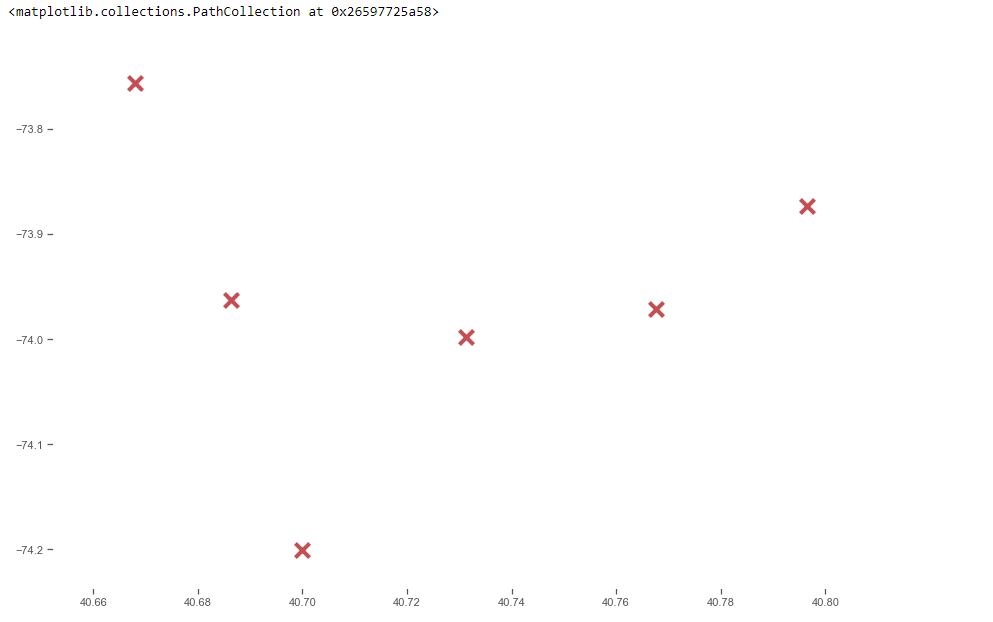
Yukarıdaki dağılım grafiğinde her bir kümeyle ilgili tüm ağırlık merkezlerini görebiliriz. Ancak, bu anlamlı bir bilgi göstermez. Aynı şeyi Google haritasına (enlem ve boylam) çizelim ve görselleştirelim.
Ağırlık merkezlerini seçmek ve yeri haritalamak için bir folium kütüphanesi kullanıldı.
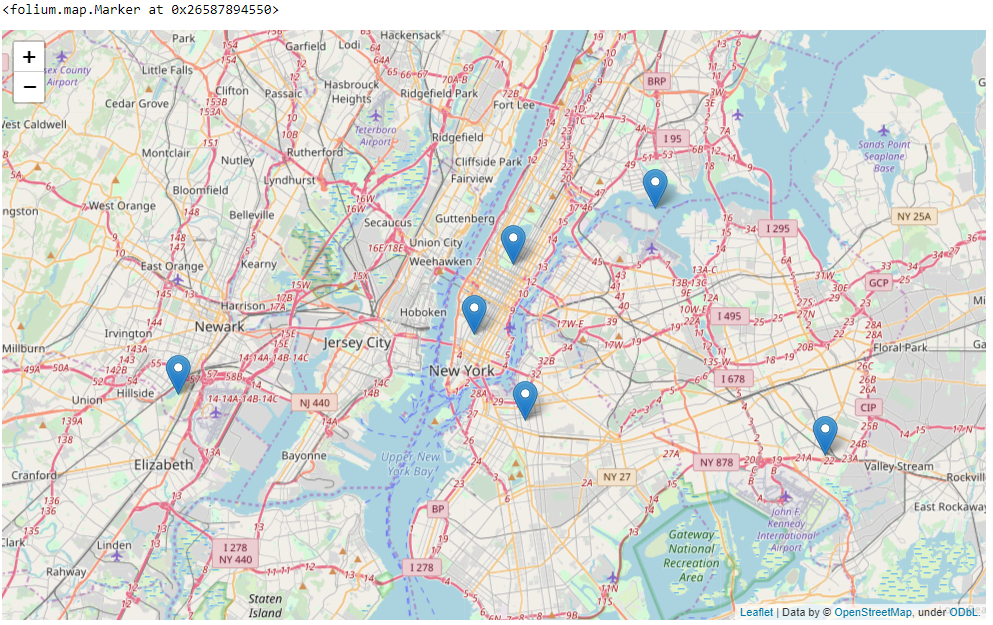
Altı ağırlık merkezinin hepsinin harita üzerinde çizildiğini görebiliriz. Bu ağırlık merkezleri Uber’e nasıl yardımcı olur?
- Uber bu ağırlık merkezlerini merkez olarak kullanabilir. Uber yeni bir sürüş talebi aldığında, bu ağırlık merkezlerlerinin her birinin yakınlığını kontrol edebilirler. Hangi belirli ağırlık merkezi daha yakınsa, Uber aracı o belirli konumdan müşteri konumuna yönlendirebilir.
- Uber’in birçok sürücüsü var ve birçok yere hizmet veriyor. Uber hub’ı (belirli ağırlık merkezi) biliyorsa ve çok fazla sürüş isteği alıyorlarsa, stratejik olarak şoförlerini, sürüş isteği alma olasılığının büyük olduğu iyi bir yere yerleştirebilirler. Bu, araçlar konuma daha yakın yerleştirildiğinden Uber’in müşteriye daha hızlı hizmet etmesine yardımcı olacak ve aynı zamanda işlerini büyütmeye yardımcı olacaktır.
- Uber, bu ağırlık merkezlerini araçlarının en uygun şekilde yerleştirilmesi için kullanabilir. Günün hangi kısmına daha fazla sürüş talebi geldiğini bulabilirler. Örneğin, Uber 11: 00’da ağırlık merkezi 0’dan (küme 1) daha fazla istek alırsa, ancak ağırlık merkezi 3’ten (küme 4) çok daha az talep alırsa, araçları küme 4’ten küme 1’e yönlendirebilir (küme 4’te daha fazla araç varsa).
- Uber, hangi kümelerin maksimum istekler, yoğun zamanlar vb. İle ilgili olduğunu analiz ederek bu ağırlık merkezlerini en uygun fiyatlandırma için kullanabilir. Varsayalım ki, belirli bir konuma gönderilecek çok fazla araç yoksa (daha fazla talep), en uygun fiyatlandırmayı yapabilirler. çünkü talep yüksek ve arz daha az.
Kümeleri Depolama

Hangi küme maksimum sürüş talebi alır?

 Küme 3, maksimum küme isteğini alır ve ardından küme 1 alır. Uber, daha yüksek talepleri karşılamak için Küme 3’e daha fazla araç yerleştirebilir.
Küme 3, maksimum küme isteğini alır ve ardından küme 1 alır. Uber, daha yüksek talepleri karşılamak için Küme 3’e daha fazla araç yerleştirebilir.
Yeni konum kontrolü
Uber yeni bir sürüş talebi alırsa (yeni konumlarını boylam ve enlem yoluyla alırken) enlem ve boylam değerini geçerse, o zaman araçtan hangi kümenin gitmesi gerektiğini tahmin eder?

array([2])
Bu durumda, araç küme 2’den gelecektir.
Kaynak: https://towardsdatascience.com/how-does-uber-use-clustering-43b21e3e6b7d




Yorum yapın